Olá, pessoal!
Estou enfrentando um erro recorrente ao utilizar um Agente de IA no Pipefy, mesmo estando no plano Business, e gostaria de entender melhor os limites e boas práticas.
📌 Cenário:
-
Plano Business
-
Agente de IA configurado para leitura e análise de laudos/exames médicos
-
Uso de um database de campanhas
-
Cada campanha possui aproximadamente 80 arquivos em PDF, contendo exames e prontuários digitalizados
-
Os PDFs são anexados em um campo de anexo do database
-
O agente é disparado quando o campo “Autorizar Processamento por IA?” = Sim
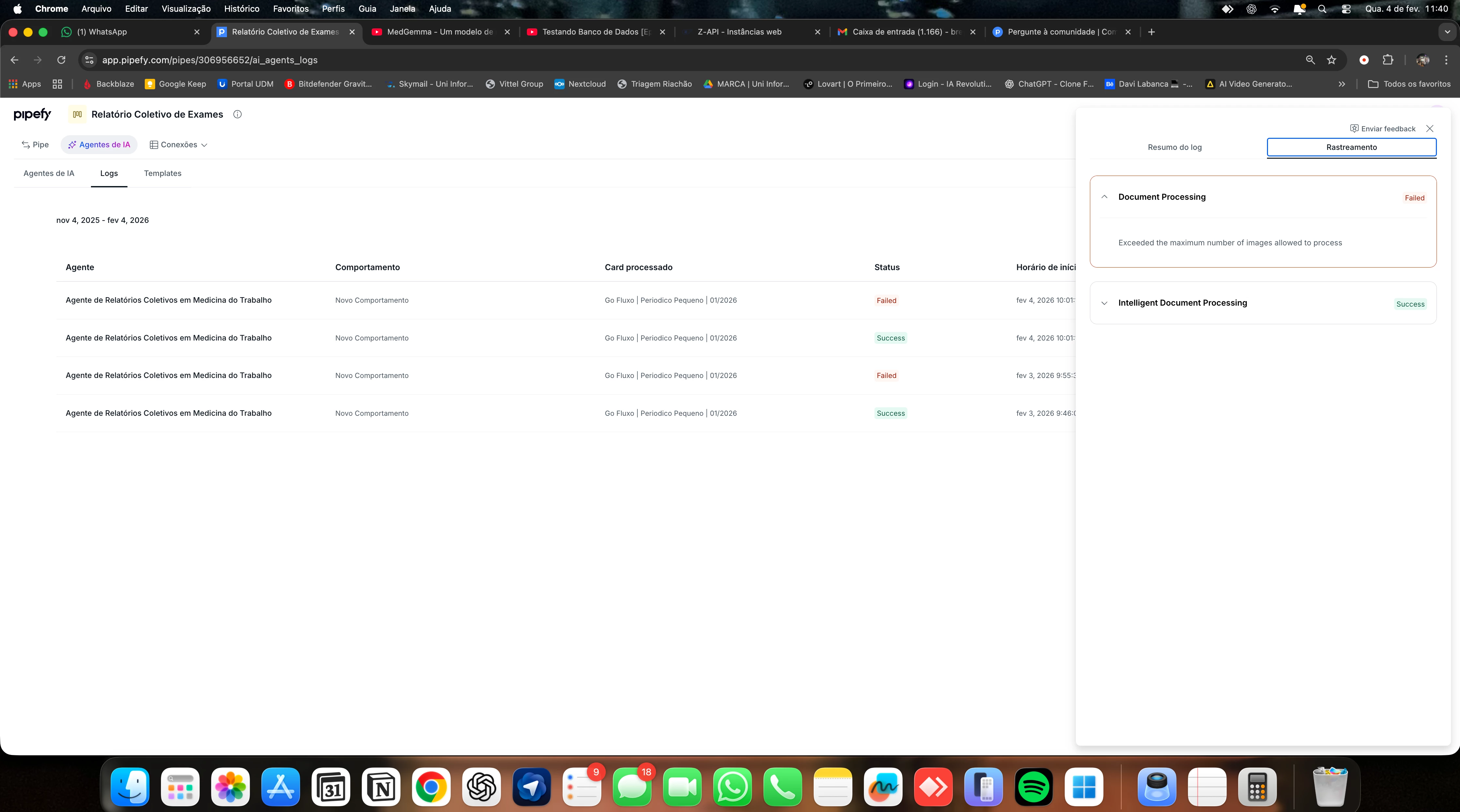
📄 Erro apresentado nos logs:
Document Processing – Failed
Exceeded the maximum number of images allowed to process
O erro ocorre de forma consistente quando há muitos PDFs anexados, impedindo a leitura completa dos laudos. O objetivo é que o agente consiga ler e interpretar os exames para gerar um relatório coletivo.
❓ Minhas dúvidas são:
-
Quais são os limites reais do campo de anexo para processamento por IA?
-
Quantidade de arquivos?
-
Quantidade de páginas por PDF?
-
Quantidade total de imagens extraídas dos PDFs?
-
-
Esses limites são globais do produto ou variam conforme plano (Business vs Enterprise)?
-
Existe alguma forma recomendada de contornar essa limitação, por exemplo:
-
dividir os anexos em múltiplos cards?
-
separar os PDFs por lote?
-
usar mais de um campo de anexo?
-
-
Qual a melhor arquitetura dentro do Pipefy para permitir que a IA consiga ler grandes volumes de laudos sem falhar?
A ideia é manter tudo governado dentro do Pipefy, mas preciso viabilizar a leitura dos exames pelo agente sem esbarrar nesses erros.
Agradeço desde já qualquer orientação ou experiência compartilhada 🙏

