Olá pessoal! Tudo certo?
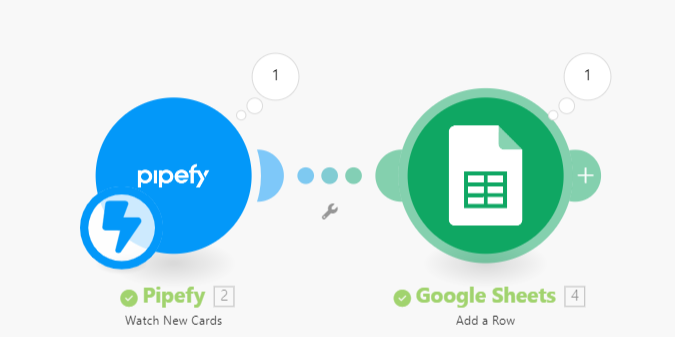
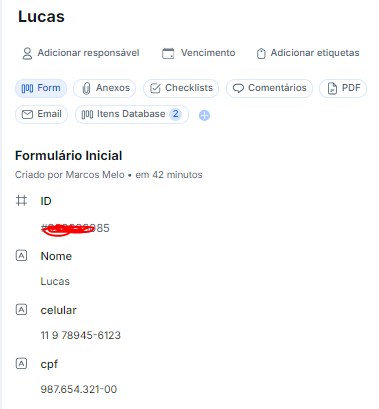
Utilizando o Make, eu consegui exportar uma Database de Candidatos a partir de uma Query.
Porém, estou com um problema onde para cada candidato, a ordem das informações é exportada diferente no output, exemplo:
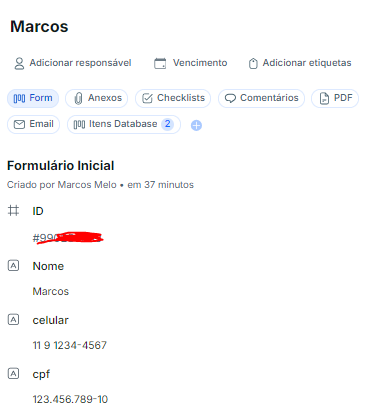
Linha 1 = Nome, celular, idade, CPF
Linha 2 = Celular, nome, CPF, idade
Linha 3 = CPF, idade, nome, celular
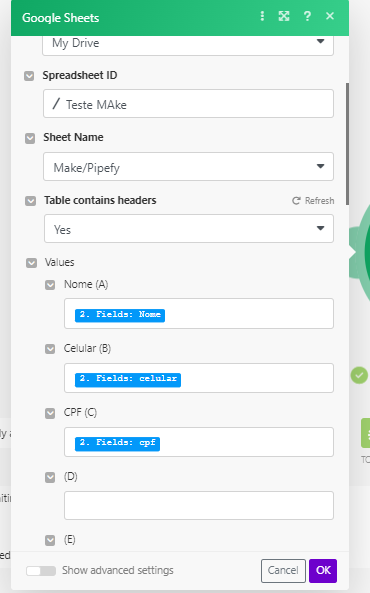
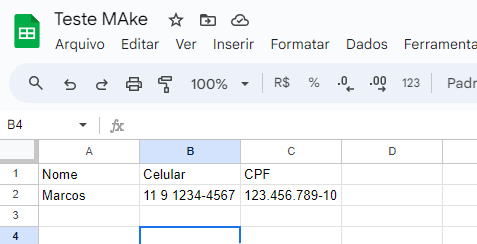
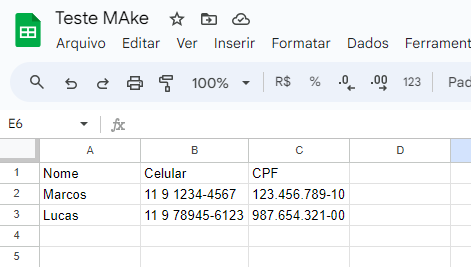
Dessa forma, não consigo padronizar a impressão dos dados em uma planilha, pois a coluna “Nome” fica com dados que realmente são nomes, porém com celulares em algumas linhas, cpf em outras e assim por diante.
Alguém sabe como posso resolver isso no Make e definir a ordem que quero imprimir na planilha?
Talvez se tiver como construir uma validação, exemplo: Se o nome do campo for “Nome”, coloque na posição 1
Obrigado!
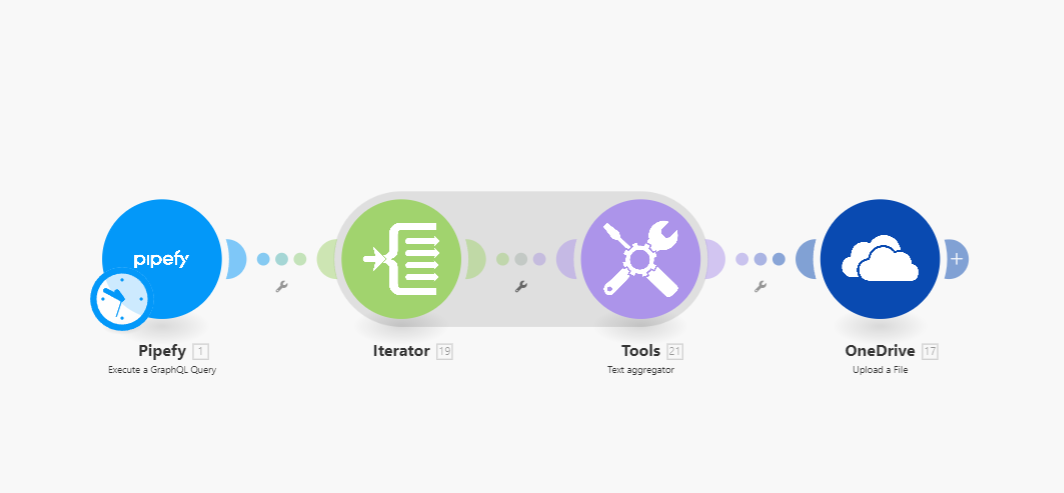
Meu processo atual é:
Todo dia as 8:00h executo a Query > Iterator para repetir o processo para cada “edge”, pois é uma coleção e cada um é um candidato, contem as informações de cada candidato > Text aggregator para montar a String separada por virgulas > Upload de uma planilha no One Drive onde cada linha é um candidato, em arquivo .csv
“Felipe, 999.999.999-00, 45 anos, (99) 99999-9999, São Paulo, SP, Administrador”
“João, 999.999.999-00, 23 anos, (99) 99999-9999, Assis, SP, Gerente”
“Fulano, 999.999.999-00, 36 anos, (99) 99999-9999, Londrina, PR, Vendedor”
Se souberem alguma forma de melhorar o fluxo, melhor ainda! Talvez eu esteva colocando módulos desnecessáiros.
Talvez seja possível já criar a planilha em .xlsx e tudo separadinho por coluna, certinho…
Obrigado pessoal!