Hello,
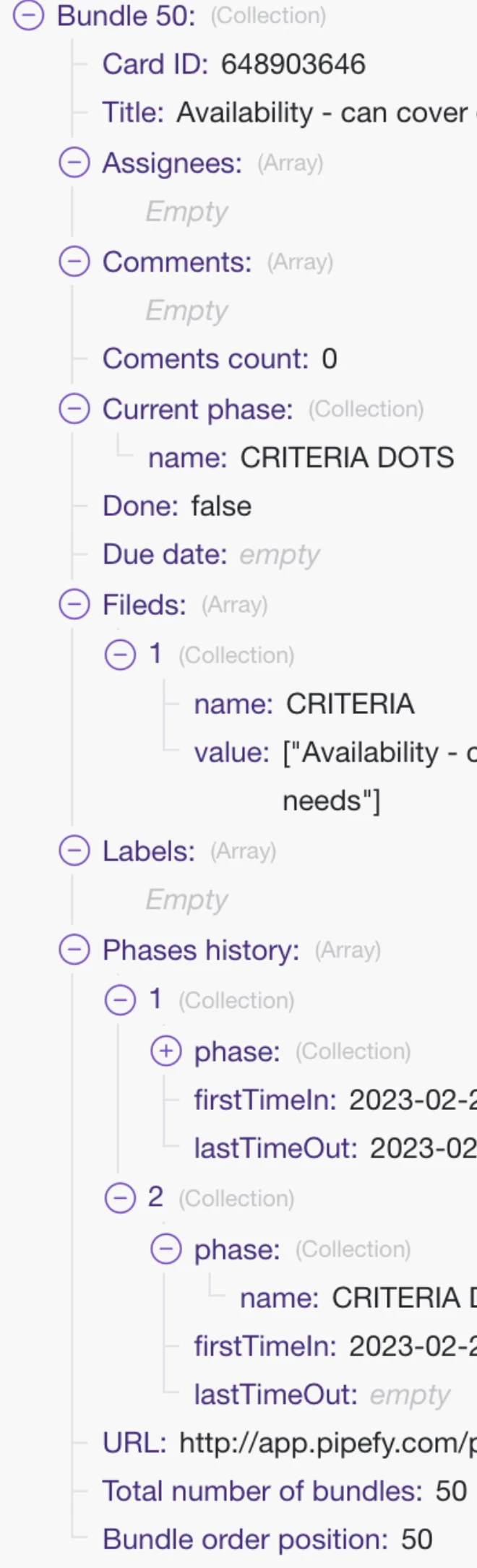
I am using Make.com (ex Integromat) to download info for all cards in a Pipe. This info includes card ID, parent relations and all card fields.
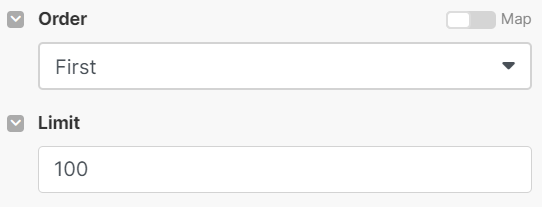
I have tested different modules that List Cards and Execute GraphQL queries. However, in all cases, I only get 50 results (bundles). And the issue is there are over 3k cards in a pipe.
Could you please recommend a way to get around this limitation and get the full info for all cards in a pipe at once?
Thanks!